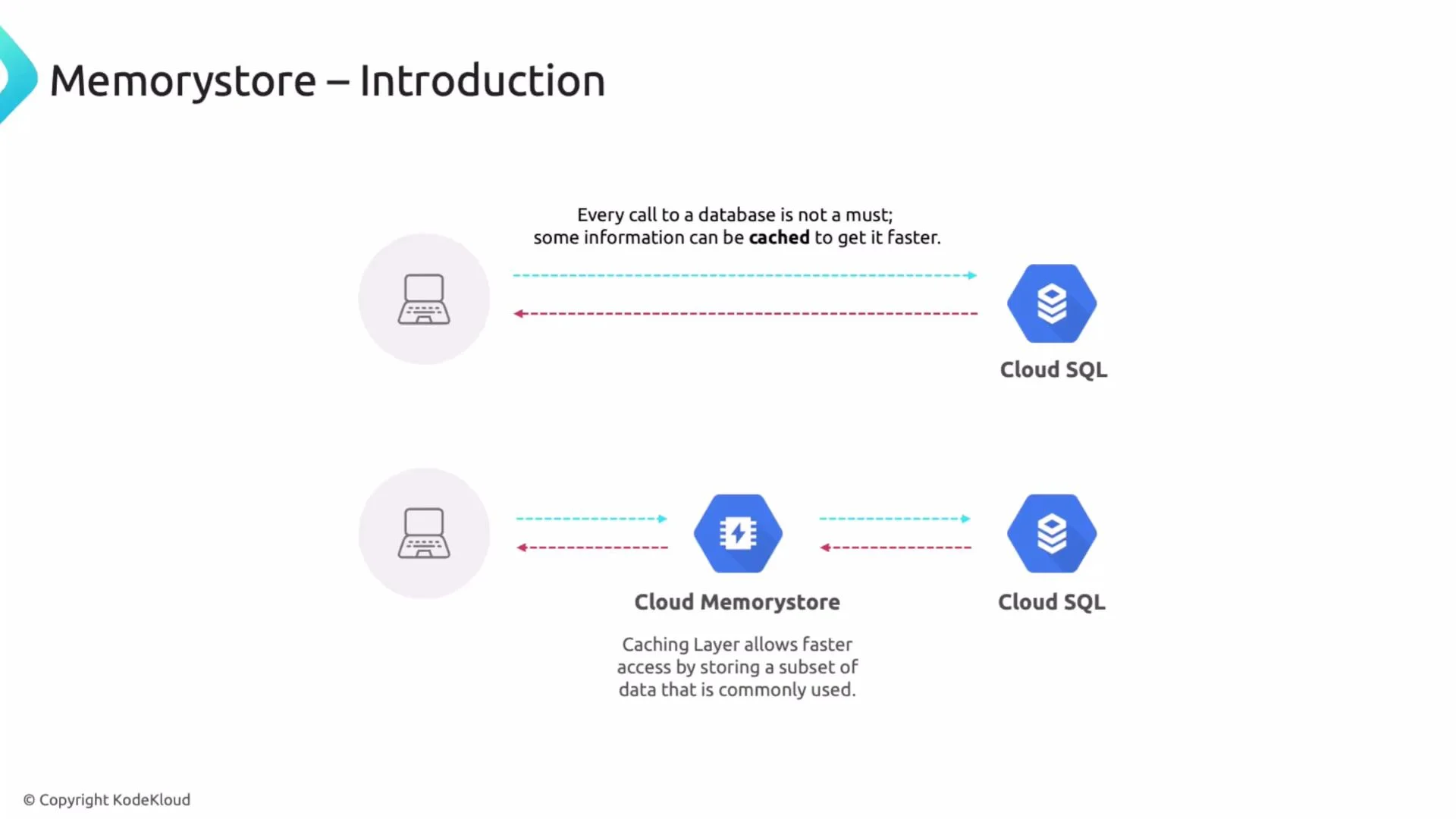
- A service queries Cloud SQL on each user request for product info.
- Repeated requests for the same product create unnecessary database load and higher latency.
- Add Cloud Memorystore as a cache layer: the service checks the cache first, falling back to Cloud SQL only on cache misses.
- The service asks the cache (Cloud Memorystore) for a value.
- If the value exists (cache hit), return it immediately.
- On a cache miss, load from Cloud SQL, return to the client, and write the value into the cache for future requests.
A common and safe pattern is cache-aside (lazy loading): check the cache first; on a miss, load from the database and populate the cache. Alternative patterns include write-through, write-behind, and read-through — choose based on your consistency and performance requirements.
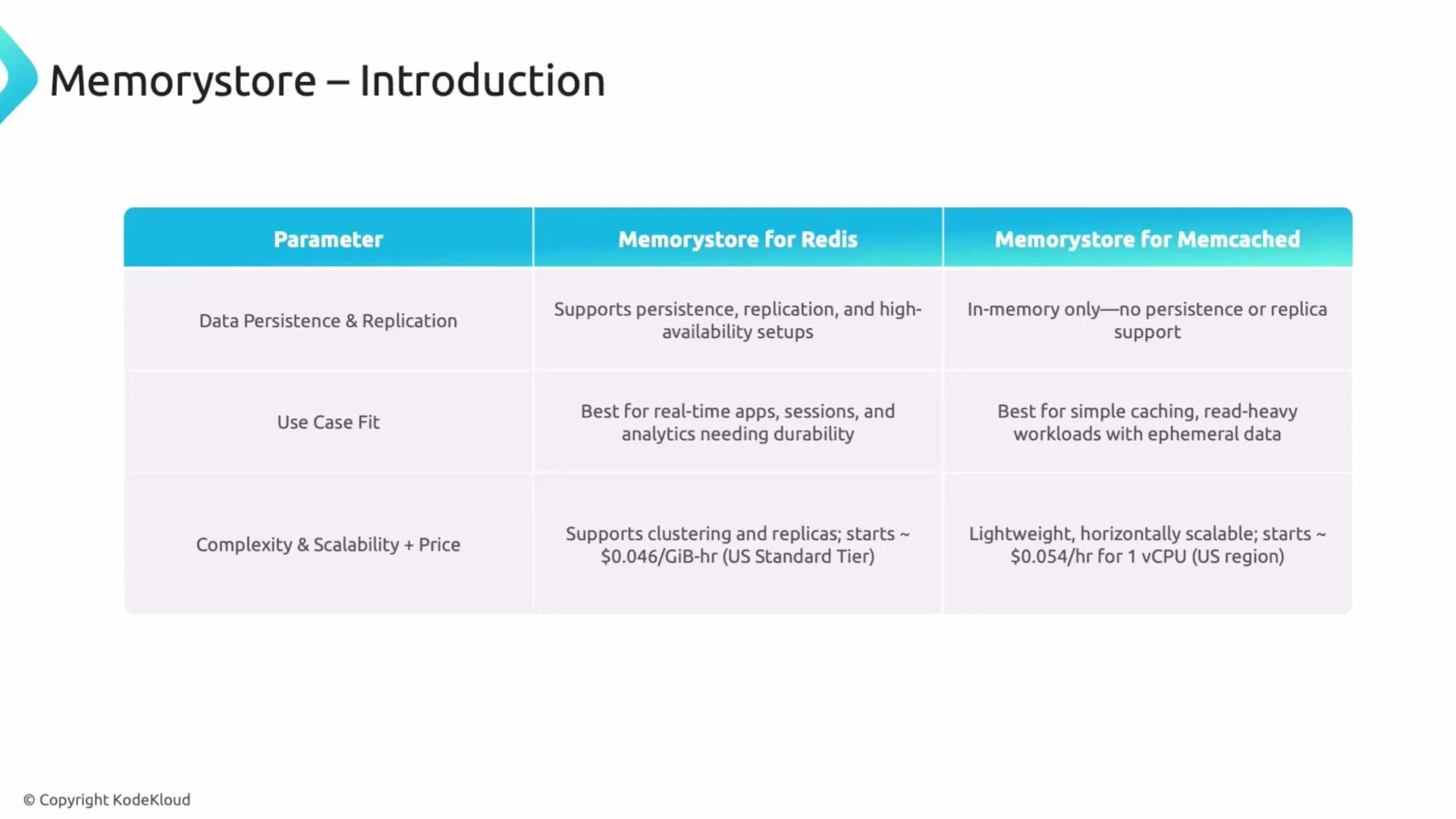
- Memorystore for Redis
- Memorystore for Memcached
In practice, teams often pick Redis for production workloads that need durability, advanced data structures, and HA. Memcached works well when your primary goal is a low-cost, simple cache.
- Eviction policy & TTL: Choose eviction policies (LRU, TTL) and time-to-live values that reflect how stale data can be.
- Cache invalidation: On writes, invalidate or update related cache keys to avoid serving stale data.
- Warm-up strategies: Preload caches or use gradual ramp-up to avoid a cold-cache spike.
- Monitoring: Track hit rate, miss rate, latency, and eviction events to tune sizing and autoscaling.
- Security & networking: Use VPCs, authorized networks, and IAM to restrict access to Memorystore instances.
Be careful with cache invalidation. Incorrect invalidation can lead to stale reads. Decide whether your application tolerates eventual consistency or requires strict consistency, then design cache write/update flows accordingly.
- Use Cloud Memorystore to dramatically reduce latency for repeated reads and to offload traffic from Cloud SQL or Firestore.
- Choose Memorystore for Redis when you need durability, HA, and advanced data structures.
- Choose Memorystore for Memcached for simple, cost-effective, transient caches.
- Implement a cache strategy (cache-aside, write-through, etc.), set TTLs/eviction policies, and monitor hit rates to tune performance.
- Cloud Memorystore documentation
- Redis documentation
- Memcached documentation
- Cloud SQL documentation
- Google Cloud best practices for caching