- Hadoop (MapReduce)
- Spark (batch and fast analytics)
- Hive (SQL-on-Hadoop)
- Pig
- Presto / Trino (interactive SQL queries)
- Flink (streaming)
- Optional tools: Iceberg, Trino, and other ecosystem components you can enable on a cluster
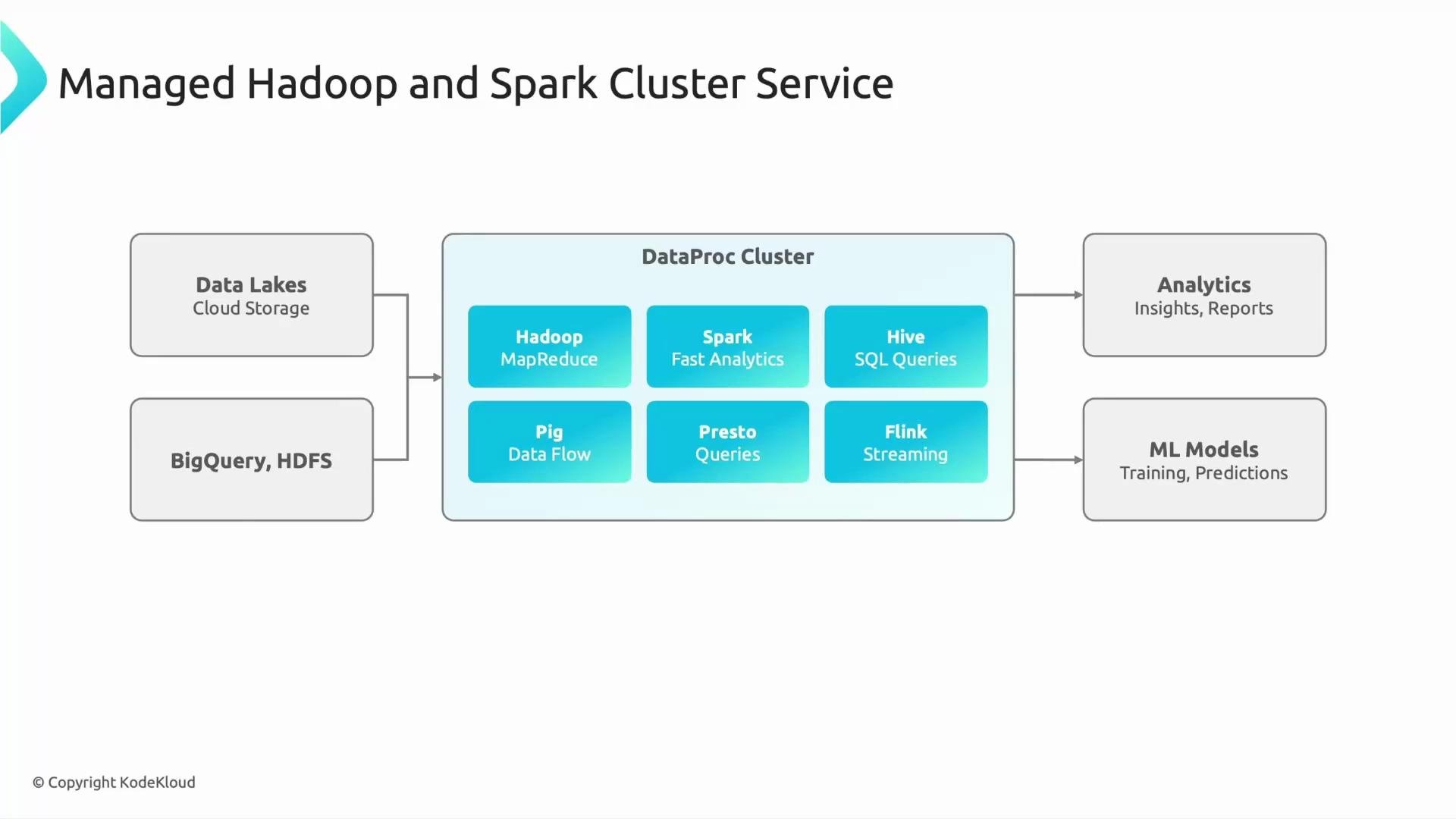
- Spin up a Spark cluster in minutes.
- Run Spark jobs against Cloud Storage input.
- Persist results to Cloud Storage or load them into BigQuery for dashboards.
- Feed processed data into ML model training.
- Fast provisioning — clusters can be created in roughly 90 seconds, enabling rapid iteration.
- Autoscaling — clusters can grow or shrink to match demand (covered in a later article).
- Open-source compatibility — reuse your existing Hadoop/Spark/Hive tooling and libraries.
- Tight GCP integration — native access to Cloud Storage, BigQuery, Cloud Logging, Cloud Monitoring, IAM, and more.
- Cost efficiency — per-second billing, support for preemptible (Spot) worker VMs, and ephemeral clusters for short-lived jobs.
Quick CLI examples
- Create a basic Dataproc cluster:
- Submit a Spark job:
- Create an ephemeral cluster, run a job, then delete it (example workflow):
- Use ephemeral clusters for ad-hoc or short batch jobs.
- Choose preemptible (Spot) worker VMs for non-critical tasks to save up to 80% on compute costs.
- Combine autoscaling with job-driven cluster policies to right-size resources.

Tip: For short batch jobs, consider creating ephemeral clusters (spin up, run the job, then delete the cluster) and using preemptible/Spot worker nodes to reduce cost. Dataproc’s per-second billing further minimizes charges for brief workloads.
- fast provisioning,
- open-source compatibility,
- deep GCP integration,
- and cost-efficient execution of batch and interactive analytics workloads.
- Google Cloud Dataproc documentation
- Cloud Storage
- BigQuery
- Google Cloud Logging
- AWS EMR (for comparison)