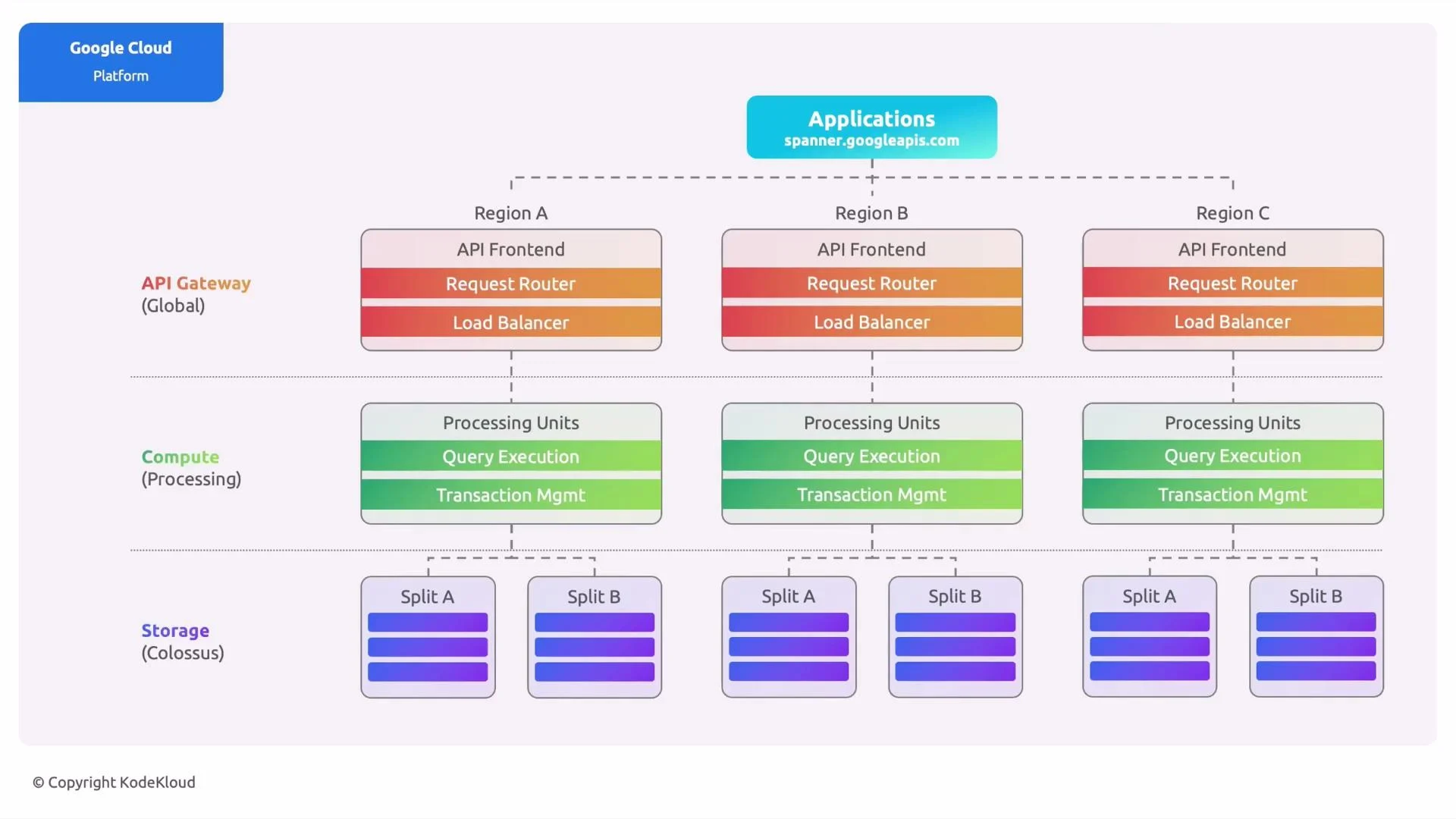
High-level request flow
- Clients target a database but all requests are sent to the global endpoint:
spanner.googleapis.com. - A global API gateway handles authentication, authorization, and routes traffic to the nearest regional frontend.
- Regional frontends and request routers forward requests to local processing units for query execution and transaction coordination.
Per-region processing units
Each region runs processing units that implement Spanner’s execution engine. Responsibilities include:- Planning and executing reads and writes
- Coordinating transactions across replicas
- Interacting with the storage layer to read/write splits (tablets)
TrueTime and external (linearizable) consistency
A core Spanner innovation is TrueTime: a globally synchronized clock service that provides a bounded uncertainty interval. TrueTime enables:- A globally-agreed ordering of transactions
- Spanner’s commit-wait protocol, which uses TrueTime uncertainty bounds to ensure external consistency (linearizability) across regions
Storage: Colossus and splits (tablets)
Spanner’s storage layer sits on Colossus, Google’s distributed file system. Instead of one monolithic file, Spanner partitions data into contiguous key ranges called splits (also called tablets). Important characteristics:- Each split is replicated according to the instance’s replication policy (single-region, multi-region, or custom multi-region).
- Replicas are placed across regions for availability and locality.
- Leader replicas handle primary writes; followers serve reads and replicate state.
How Spanner achieves scalability and availability
Key design choices that enable Spanner’s global scale and high availability:- Replication: Each split is replicated across zones/regions for fault tolerance and locality.
- Automatic split management: Ranges are split and merged dynamically based on load and size.
- Leader election and placement: Leaders are placed to optimize latency and availability; elections ensure continuity when failures occur.
- Commit-wait (TrueTime): Ensures transactions are externally consistent across regions.
- Local processing units: Keep query planning and transaction coordination close to replica data and clients.
Quick reference: architecture layers
Deployment and replication options
For more details on configuration and pricing, see the Cloud Spanner documentation: Cloud Spanner Documentation.
Exam tip: Cloud Spanner is a globally distributed relational database that provides strong (external) consistency and horizontal scaling. Remember: global, strongly consistent, horizontally scalable.
Cost note: Cloud Spanner is generally more expensive than single-region relational options (e.g., Cloud SQL) because it provides global replication, automatic split management, and TrueTime-driven consistency. Choose Spanner when you need global consistency and high availability; for smaller or single-region use cases, consider lower-cost alternatives.