Data Ingestion and Storage
AWS Lake Formation aggregates data from a variety of sources including DynamoDB, Redshift, S3, RDS, Aurora, and even the AWS Glue Data Catalog. The ingestion process operates much like AWS Glue—a serverless data integration service that crawls your data sources to populate the Glue Data Catalog with metadata. This process can be scheduled at regular intervals (for example, every two hours or every 24 hours) to ensure your data lake remains current. After ingestion, data is centrally stored in S3 in its native format (CSV, TSV, etc.) or in analytics-optimized formats such as Apache Parquet or ORC. These optimized formats greatly enhance query performance, especially when using services like Athena. The data is subsequently cataloged as tables in the Glue Data Catalog, simplifying data management and enforcing granular access control. The diagram below illustrates the key components of AWS Lake Formation, highlighting data ingestion, storage, and processing: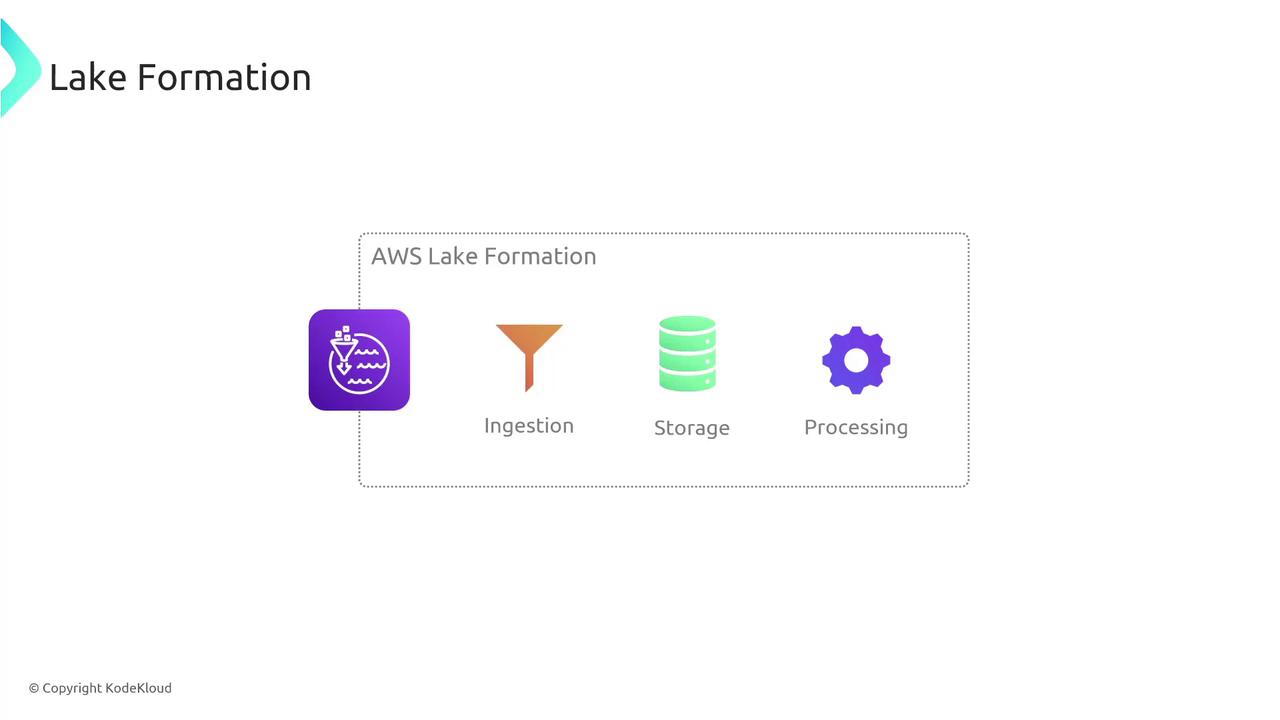
Data Processing
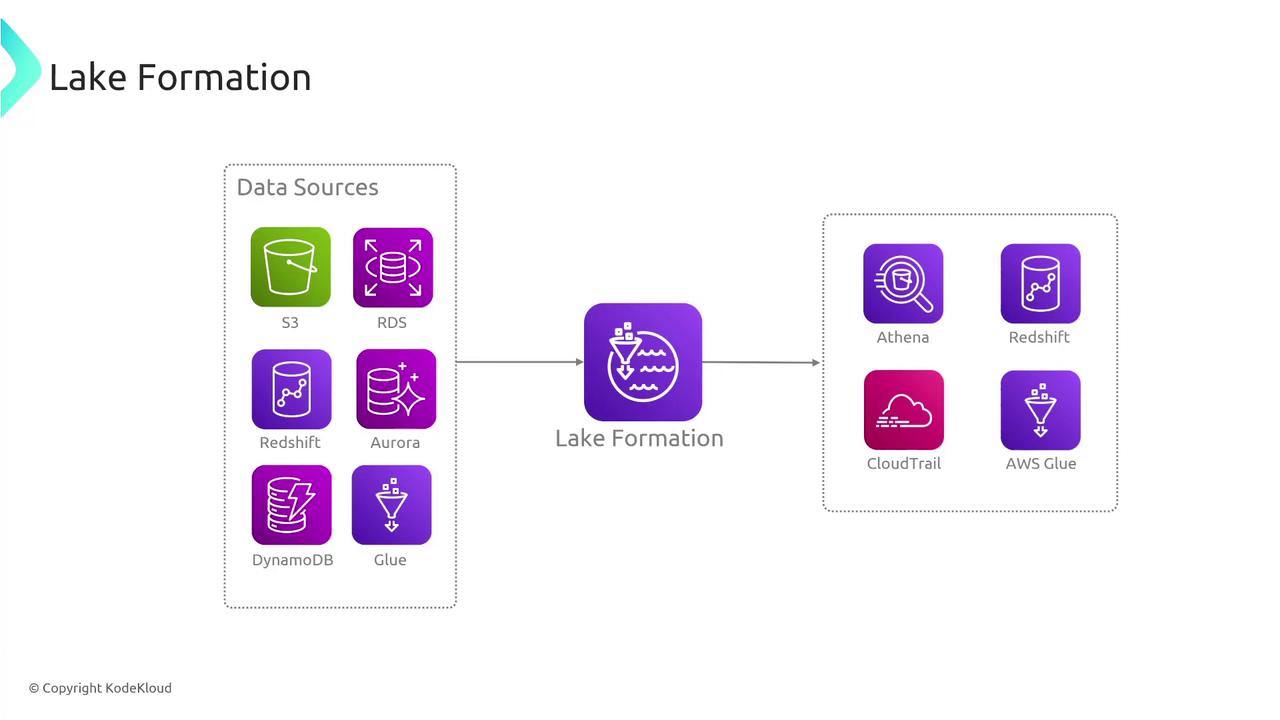
Once data is ingested and stored, Lake Formation leverages AWS Glue jobs to process the data. These ETL (Extract, Transform, Load) jobs enrich and transform data, preparing it for downstream services such as Athena, Redshift, EMR, or various machine learning platforms. To summarize the process:- Data is ingested from multiple sources and registered in the Glue Data Catalog.
- Data is stored in S3 and optionally converted into analytics-optimized formats (e.g., Parquet or ORC).
- AWS Glue ETL jobs process the data, making it accessible for querying and further analysis.
Integration with Other AWS Services
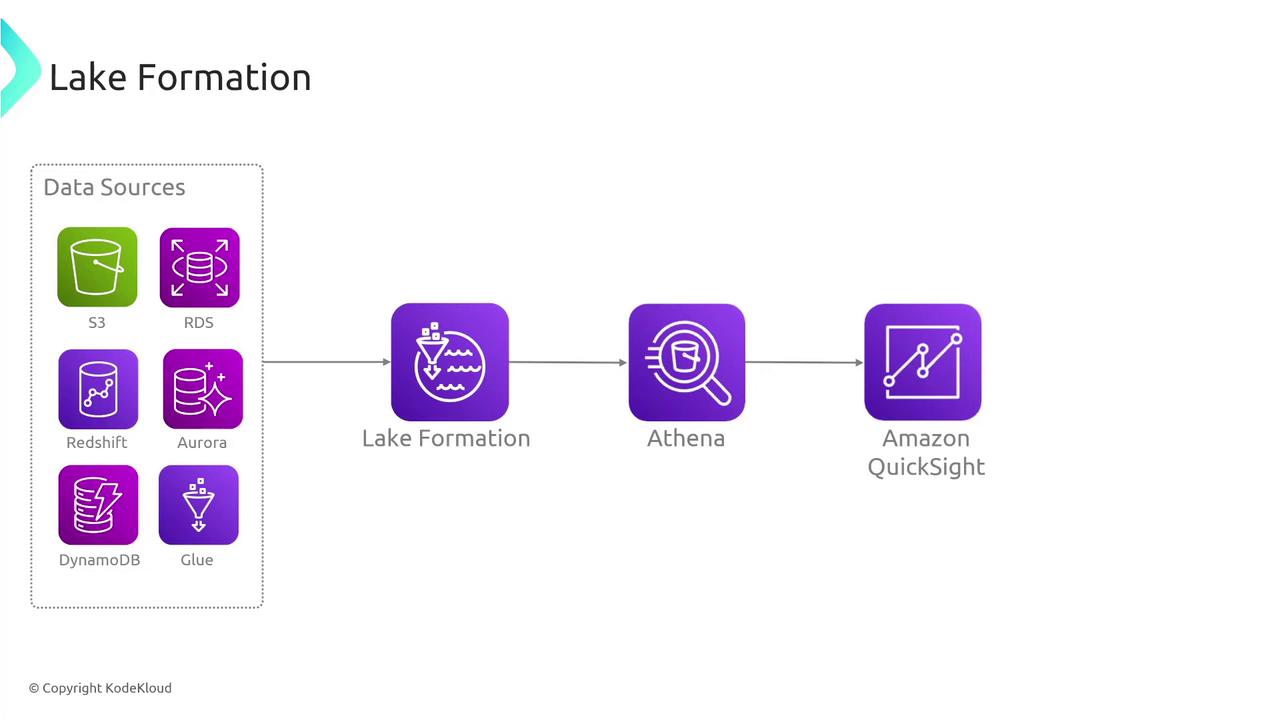
AWS Lake Formation integrates effortlessly with various AWS services, enabling comprehensive data consumption and analysis:- Athena: Executes queries on data stored in optimized formats, resulting in improved performance and cost reduction.
- QuickSight: Offers advanced data visualization capabilities by querying Athena, which facilitates dynamic dashboards and in-depth analytics.
- Additional Services: AWS Glue can perform further data transformations, while CloudTrail logs API calls made against Lake Formation for complete monitoring and auditing.
Key Features of AWS Lake Formation
AWS Lake Formation simplifies the creation of a modern data lake by centralizing data access and employing advanced techniques such as data deduplication through built-in machine learning algorithms. Additionally, the service supports cross-region data replication, enhancing data durability, disaster recovery, and compliance with data residency requirements.- Centralized data management and control
- Optimized storage formats for enhanced query performance
- Automated metadata extraction and cataloging via AWS Glue
- Comprehensive monitoring and auditing with CloudTrail integration