This article explores AWS Textract, a machine learning service for automatically extracting text and data from scanned documents.
Welcome back, Solutions Architects. In this article, presented by Michael Forrester, we explore the power of language processing with AWS Textract—a fully managed machine learning service designed to automatically extract text and data from scanned documents.Textract efficiently processes various document types, such as handwritten notes, PDFs, and more, converting them into standardized digital formats that include tables, formatted text, and key data points. Once the extraction is complete, you can either download the data or store it in a database to meet your business requirements. For example, imagine medical reports being ingested into a HIPAA-compliant database to enhance patient-doctor communication, improve accuracy, and provide deeper insight through detailed analyses.
Textract enables you to:
Extract raw text from documents.
Identify key-value pairs by correlating form data with extracted text.
Extract structured table data.
Recognize signatures within documents.
Return results in multiple formats (JSON, CSV, TXT).
Execute queries against specific document information.
In addition to text extraction, AWS Textract also supports form and table extraction, as well as signature recognition. Its seamless integration with other AWS services, such as Lambda, makes it possible to build robust document processing pipelines. For example, you can send the extracted text to AWS Comprehend for sentiment analysis, thereby chain-processing your documents without any hassle. Its scalability is exceptional—even when working with challenging handwritten texts, Textract often requires minimal post-processing corrections.In my own experience, I have tested Textract with some of the most challenging handwritten notes in English. Despite encountering a few minor errors with technical jargon, the service consistently produced meaningful, usable text with very little editing required.
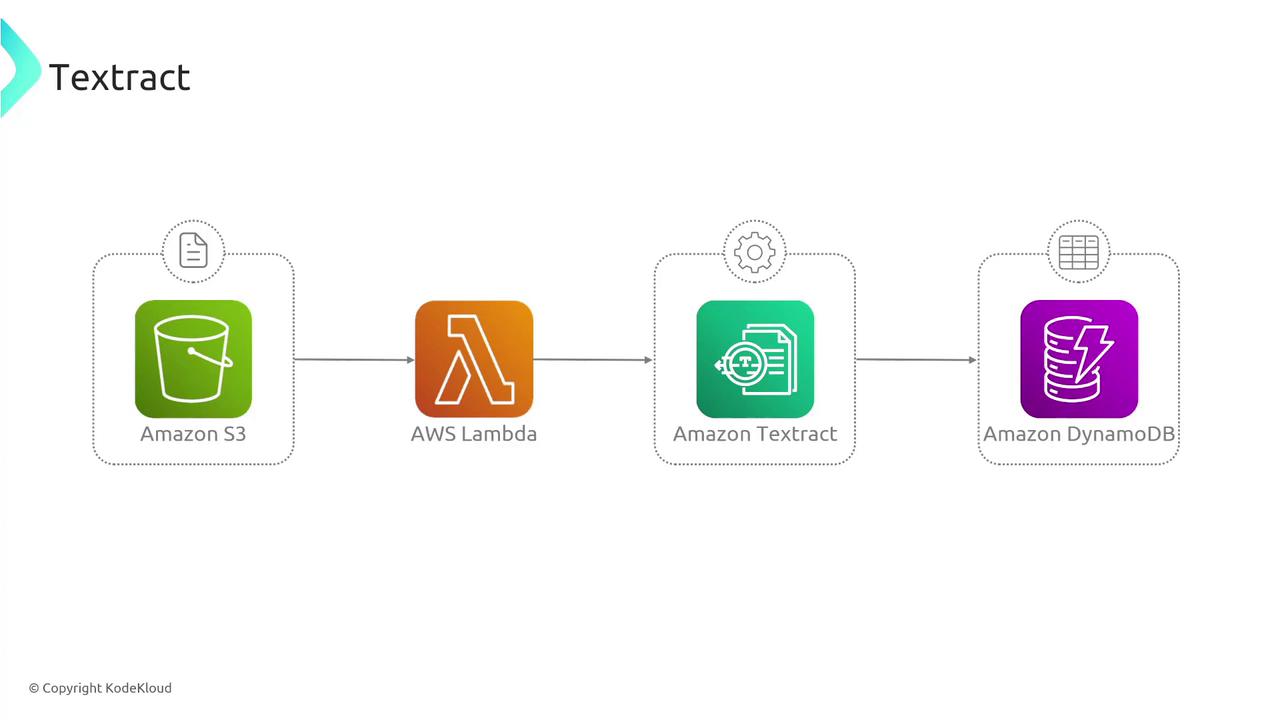
Textract’s scalability is practically limitless. I have processed millions of documents in just a few hours—all without the need for specialized machine learning expertise.The typical architecture of Textract follows this process:
Documents are sourced and stored in Amazon S3.
An AWS Lambda function is triggered to call Textract.
Textract processes the document.
The extracted data is output back to S3 or can be directly downloaded via the AWS Management Console.
For those new to AWS Textract, I recommend uploading a sample document with handwritten notes to your AWS account and observing how Textract transforms it into digital text.In another example workflow, after Textract processes a document uploaded to S3 through a Lambda function, the extracted text is stored in a DynamoDB table. This structured data can then be retrieved for further processing or analysis.
This article has covered the core functionality of AWS Textract: extracting text from scanned documents and converting it into a digital format for further use. If you have any questions or need further assistance, please join us on Slack. We look forward to connecting with you in our next lesson.