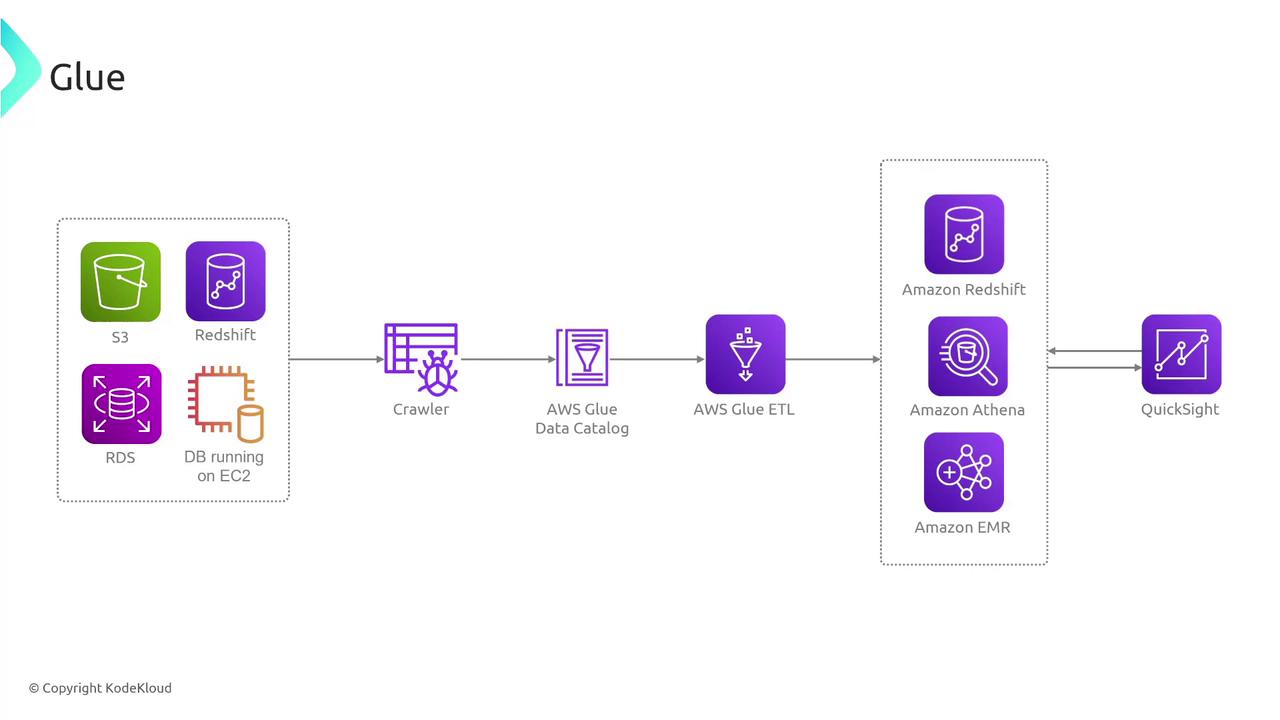
Key Components of AWS Glue
AWS Glue is built around three main components that work together to streamline your data workflows:-
Crawler
The crawler automatically connects to data sources (such as S3 buckets or RDBMS systems) to scan for data. It then populates the Glue Data Catalog with table definitions and associated metadata. This centralized catalog maintains both raw data references and the critical structural metadata required for ETL operations. -
ETL Jobs with Apache Spark and PySpark
AWS Glue supports ETL jobs that can be authored manually in Spark or PySpark, or you can use prebuilt scripts provided by Amazon. These jobs extract data from cataloged sources, apply transformations—including renaming fields, filtering records, joining datasets, or aggregating information—and load the transformed data into target destinations like S3, Redshift, Athena, or QuickSight. -
Visual Interface with Glue Studio
Glue Studio provides a user-friendly Integrated Development Environment (IDE) for creating, testing, and monitoring Apache Spark jobs visually, eliminating the need for managing local environments or physical infrastructure.
How AWS Glue Works
The diagram below illustrates a typical data processing workflow using AWS Glue. It shows the flow from a data source through extraction, transformation, and loading stages into a data target, with the Data Catalog maintaining vital metadata: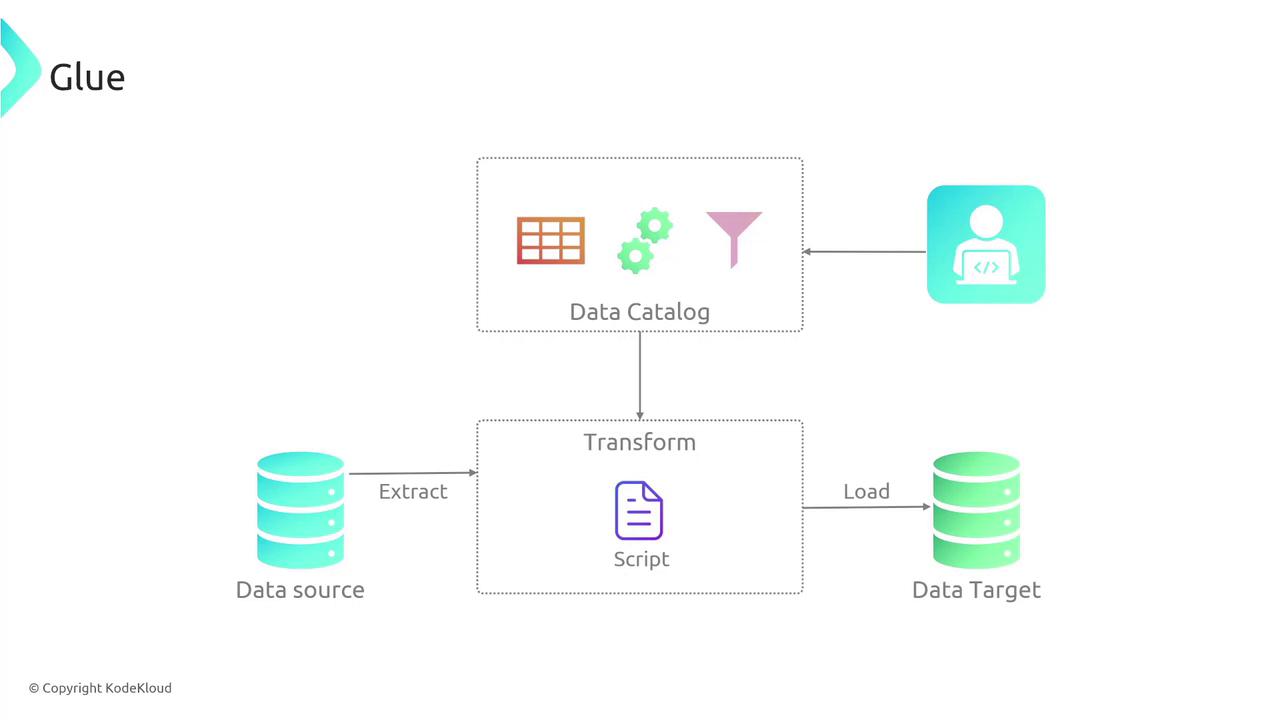
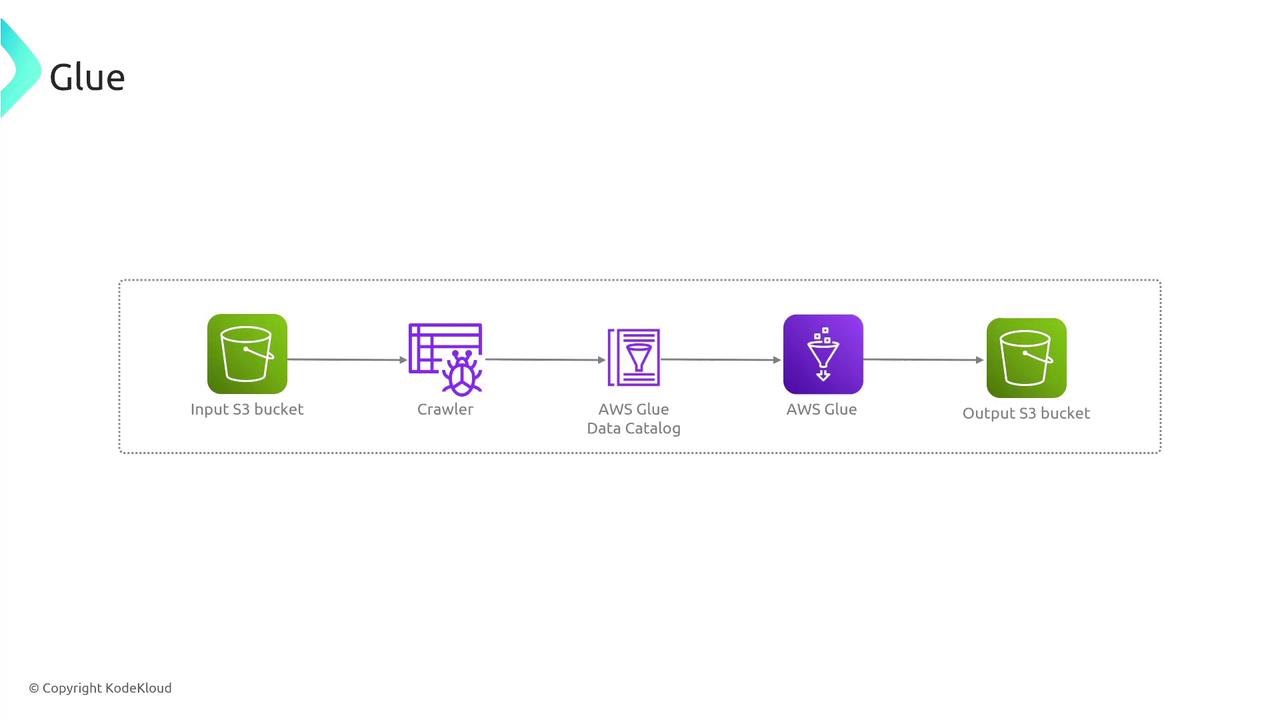
AWS Glue’s serverless nature means you can focus on developing your ETL processes without worrying about the underlying infrastructure.
Built-in Transformation Libraries and Glue Studio
AWS Glue also includes built-in transformation libraries—simple, reusable functionalities for common data operations such as field renaming, record filtering, and data aggregation. This means you can quickly set up data cleaning and normalization routines without coding these functions from scratch. Moreover, the Glue Data Catalog acts as a persistent metadata repository, allowing other AWS services like Athena, EMR, or Redshift to utilize the stored data effectively. Glue Studio enhances this process by offering a visual interface for designing, executing, and monitoring Spark jobs. This simplifies development, debugging, and management of ETL tasks, making it easier to maintain robust data pipelines. The image below summarizes the key features of AWS Glue, including its serverless ETL capability, centralized Data Catalog, automatic schema discovery, visual job authoring, and built-in transformation libraries: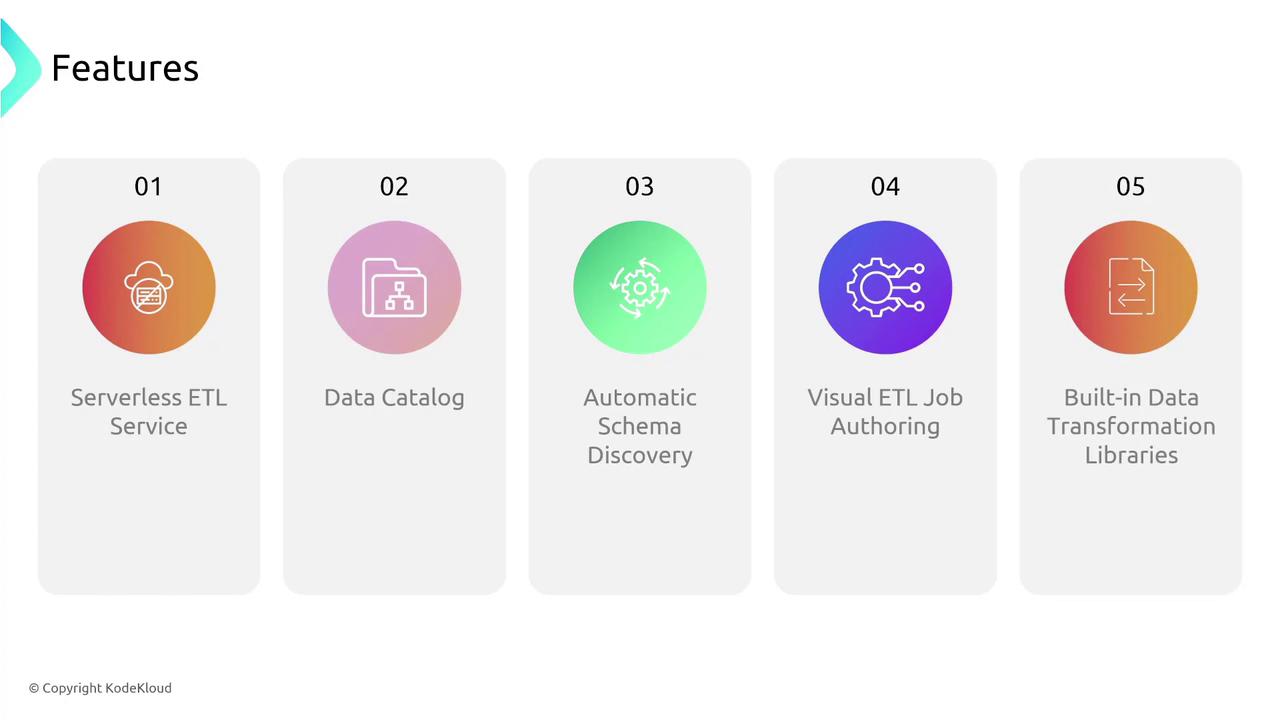
Conclusion
AWS Glue simplifies data transformation and migration across multiple platforms, supporting targets like S3, Redshift, QuickSight, and more. Its serverless model eliminates infrastructure management overhead while providing a centralized catalog that offers a consolidated view of your data assets. This makes AWS Glue an indispensable tool for modern data workflows. If you have any questions about AWS Glue, please join us on the KodeKloud Slack under AWS Courses. We look forward to sharing more insights in our next lesson.