Overview of the Challenge
When you begin the challenge, you will encounter a list of scenarios represented by specific links (e.g., security, reliability, etc.). Clicking one of these links loads an example page similar to the one shown below. On the challenge page you will find:- Instructions in the upper left-hand corner.
- A reference diagram that illustrates the target architecture.
- A palette of AWS services that you can drag into designated areas. Gray boxes in the diagram indicate the missing components that you need to identify and complete.
Example Scenario: Laboratory Instrument Logs Pipeline
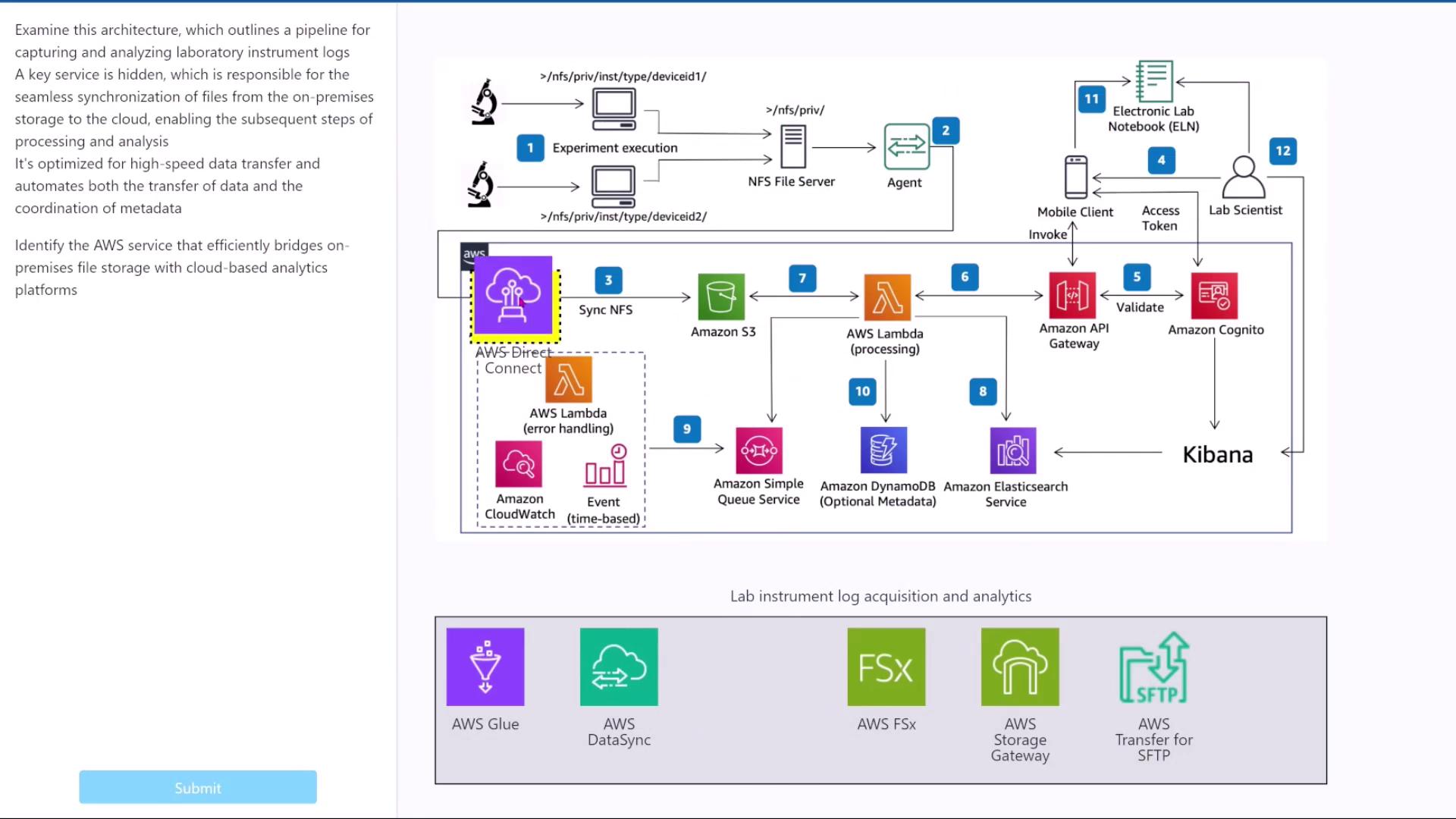
Consider a challenge where you need to design a data pipeline for capturing and analyzing laboratory instrument logs. In this scenario, an unknown AWS service is responsible for seamlessly synchronizing files from on-premises storage to the cloud, enabling efficient processing and analysis through high-speed data transfer and metadata coordination. Your task is to identify and place the appropriate service into the missing component. In the provided diagram, lab devices generate logs during experiments. An agent retrieves data from a file server and sends it to an unknown AWS service before synchronizing it with Amazon S3. Although additional components exist—such as AWS Lambda for processing, API Gateway and Amazon Cognito for authentication, and Kibana for dashboard visualization—the focus is on the storage-to-storage data transfer element. Consider these available services:- Glue: Designed for ETL tasks; it does not perform pure data synchronization.
- FSx: Provides file storage but does not support synchronization.
- Direct Connect: Sets up a network connection without data synchronization.
- Storage Gateway: Hosts on-premises storage.
- SFTP: Focused on secure file transfer.
The service that seamlessly transfers data between on-premises storage and the cloud is AWS DataSync.
Scenario Two: Development Environment Architecture
Imagine an environment where development teams require a robust monitoring system and a scalable database to manage multiple applications. In this scenario, the diagram includes three gray boxes that represent missing services for:- Container orchestration
- Application monitoring
- Database scalability
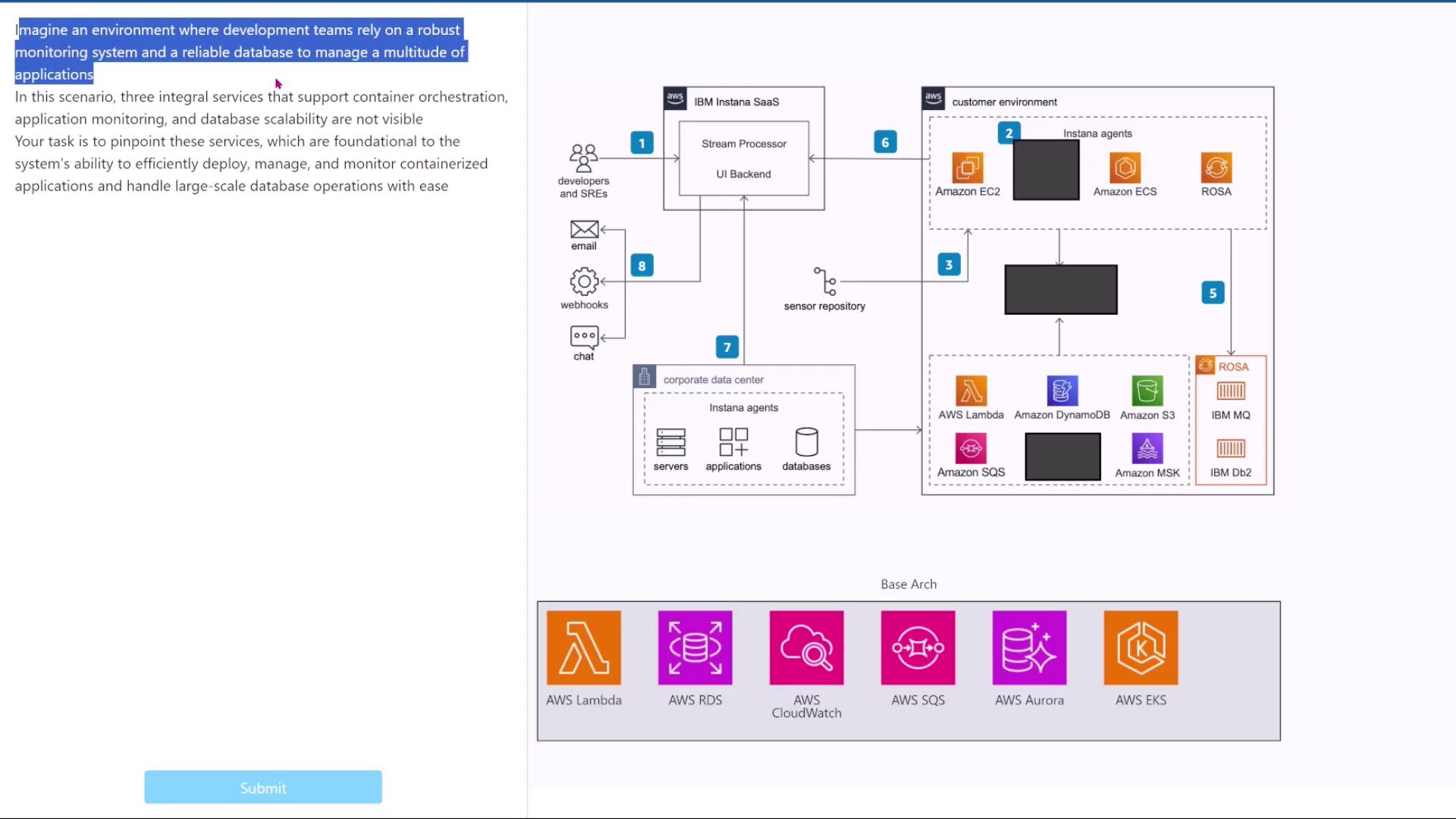
- Developers integrate with Instana SaaS, with Instana agents operating in the environment to feed sensor data.
- For container orchestration, select the service designed specifically to manage containers (not EC2, which represents virtual machines).
- For large-scale database management, choose Amazon Aurora, which is optimized for scalability compared to a traditional RDS database.
- For application monitoring, pick the service best suited to process incoming telemetry data.
Scenario Three: Advanced Contact Center Architecture
This scenario involves a sophisticated contact center designed to leverage AI to enhance customer interactions and support agents. The design integrates multiple services:- One service empowers agents with searchable enterprise information.
- A second service offers a conversational interface to interpret user queries.
- A third service synchronizes data across various sources.
- For searchable enterprise information, Amazon Kendra is the optimal choice.
- For the conversational interface, Amazon Lex provides a dedicated chat framework.
- For synchronizing data across sources, AWS AppSync is ideally suited to the task.
Final Thoughts
These challenges vary in complexity—from selecting a single service to configuring multiple integrations. The goal is to help you master the process of mapping AWS services into reference architectures effectively.If you have any questions or need clarification, please join our forums, Slack, or Discord communities.